
Los Pandora Papers revelaron cómo los políticos, las celebridades, la realeza y los estafadores utilizan los paraísos fiscales en el extranjero para ocultar activos, comprar propiedades en secreto, lavar dinero y evitar impuestos.
Más de 600 periodistas en 117 países colaboraron, utilizando herramientas de datos para extraer conexiones ocultas entre compañías extraterritoriales y élites ricas que usaban los paraísos fiscales para ocultar sus actividades financieras. Su investigación avergonzó a políticos, miembros de la realeza, celebridades y oligarcas de todo el mundo.
Los documentos de Pandora demostraron que uno de los monarcas más antiguos del mundo, el rey Abdullah II de Jordania, había construido en secreto un imperio de propiedad personal.
Su cartera, incluidas las propiedades de lujo en Malibú y Belgravia de Londres, valía más de 100 millones de dólares. Y fueron comprados en un momento en que los ciudadanos de su país enfrentaban severas medidas de austeridad y un desempleo desenfrenado. Su verdadera propiedad estaba oculta por empresas offshore registradas en las Islas Vírgenes Británicas.
En Chile, políticos de la oposición iniciaron un juicio político contra el presidente Sebastián Piñera por irregularidades en la venta de una empresa minera que fueron reveladas en los documentos.
Y en el Reino Unido, el primer ministro Boris Johnson enfrentó demandas para devolver fondos políticos de donantes del Partido Conservador con supuestos vínculos con la corrupción.
Las donaciones provinieron de un magnate petrolero nacido en Rusia y la esposa de un ex oligarca ruso cuyo marido canalizaba dinero a través de una red de empresas secretas “fantasma” extraterritoriales.
Otro donante adinerado del Partido Conservador asesoró a una empresa de telecomunicaciones suiza sobre una compleja transacción financiera que luego fue reconocida como un pago corrupto, revelan los periódicos.
Tesoro complejo
Los Pandora Papers son una de las filtraciones más significativas que ha recibido el Consorcio Internacional de Periodistas de Investigación (ICIJ).
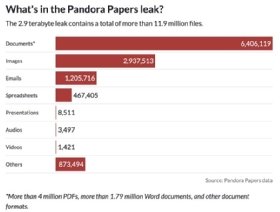
Periodistas de todo el mundo pasaron más de un año analizando el tesoro de 11,9 millones de registros de empresas extraterritoriales para descubrir historias importantes.
En los terabytes de datos se incluyeron copias de pasaportes, extractos bancarios, declaraciones de impuestos, documentos de constitución de empresas, contratos de propiedad y cuestionarios de diligencia debida, presentaciones, archivos de audio y video y notas escritas a mano.
“Estábamos hablando de documentos muy complejos”, dijo Emilia Díaz-Struck, editora de investigación del ICIJ y coordinadora de América Latina. “Estamos hablando de documentos financieros y estructuras corporativas complejas”.
Los datos procedían de 14 empresas diferentes especializadas en servicios offshore y cada una de ellas almacenaba sus datos de forma diferente.
Dar sentido a ese “lío de datos” requería una combinación de periodismo y análisis de datos sofisticado.
Solo el 4% de los datos que contenían se mantenían en hojas de cálculo. El resto no estaba estructurado y era difícil de buscar.
“Tuvimos suerte con algunos proveedores”, dijo Díaz-Struck. “Había hojas de cálculo, pero aún teníamos que combinarlas, encontrar duplicados y juntarlas en un solo archivo”.
En otros casos, la información estaba enterrada en enormes archivos PDF, que debían ser analizados y revisados por los equipos de datos y tecnología.
“El peor escenario fue cuando había formularios escritos a mano”, dijo Díaz-Struck. “Teníamos gente de nuestro equipo que extraía manualmente esa información y la ponía en un formato estructurado”.
Equipo de tecnologia
Pierre Romera, director de tecnología del ICIJ, ha pasado su carrera trabajando con fuentes sensibles, comunicaciones seguras y analizando cantidades masivas de datos.
Romera estuvo allí desde el inicio del proyecto Pandora Papers cuando el ICIJ tuvo sus primeros contactos con un informante confidencial con acceso a millones de registros de empresas offshore.
Trabaja con un equipo de aproximadamente 10 personas en tecnología que permite a los periodistas analizar enormes conjuntos de datos. El equipo incluye desarrolladores, administradores de sistemas, diseñadores y especialistas en DevOps..
Desde su trabajo pionero en la primera fuga costa afuera a gran escala en 2013, el ICIJ ha desarrollado herramientas cada vez más poderosas para indexar y buscar documentos.
La primera filtración, que se conoció como Offshore Leaks, fue pequeña en comparación con los documentos de Pandora, con solo 260 GB de correos electrónicos y bases de datos filtrados.
Esa investigación tomó callejones sin salida, cometió errores y enfrentó dificultades técnicas, pero también fue pionera en nuevos métodos de periodismo y análisis de datos, informó Computer Weekly en ese momento.
Después de experimentar con bases de datos estructuradas, incluido SQL, para analizar las fugas en alta mar, los expertos en datos del ICIJ recurrieron al software gratuito de recuperación de texto Nuix.
Los especialistas en datos también desarrollaron un portal web, utilizando otro programa de recuperación de texto libre, DT Search, que permitió a más de 100 periodistas de todo el mundo interrogar los documentos.
Para cuando se publicaron los resultados de otra importante filtración en alta mar, los Papeles de Panamá, en 2016, el ICIJ había establecido un pequeño equipo de datos dedicado y había comenzado a desarrollar sus propias herramientas de colaboración.
La filtración de los Papeles de Panamá fue mucho mayor que las filtraciones anteriores y era obvio que Nuix no encajaba bien, dijo Romera.
El equipo de datos recurrió al software de código abierto para crear un motor de búsqueda de texto libre dedicado utilizando Blacklight, una herramienta ampliamente utilizada por las bibliotecas para buscar documentos, y Apache Solr, una herramienta de búsqueda empresarial de código abierto.
Con el tiempo, el equipo de datos cambió a otra tecnología, Elasticsearch, que permitió búsquedas más rápidas.
“Elasticsearch es mucho más poderoso, tiene una enorme comunidad de código abierto y muchas características que son muy útiles para estas investigaciones”, dijo Romera.
‘La herramienta más importante que tenemos’
Ese proyecto resultó en la creación de Datashare, que Romera describe como la herramienta más importante utilizada por los periodistas del ICIJ durante las colaboraciones. Permite a los periodistas buscar vastos archivos de documentos de forma rápida y segura.
Una de las características más útiles de Datashare es su capacidad para realizar búsquedas masivas de datos. Los periodistas pueden cargar archivos que contengan, por ejemplo, listas de políticos, miembros de la realeza o celebridades para encontrar historias dentro de los vastos archivos de datos.
El intercambio de datos también es escalable, lo que permite a Romera agregar más servidores para proporcionar la potencia informática necesaria para analizar fugas más grandes y brindar soporte a equipos más grandes.
Durante el proyecto Pandora Papers, el ICIJ tenía la capacidad de implementar entre 15 y 20 servidores. Esto hizo posible que más de 600 periodistas realizaran búsquedas de palabras clave en los datos, un paso más que los más de 370 periodistas que trabajaron en los Papeles de Panamá.
“Debido a que estamos tratando de encontrar la mayor cantidad de historias en los documentos, realmente necesitamos usar este motor de búsqueda de manera intensiva”, dijo Romera.
Datashare está diseñado para ser simple y rápido de usar y es, dijo Romera, esencialmente una interfaz liviana construida sobre Elasticsearch.
Pero también puede admitir extensiones y complementos de software. Uno de los más útiles es un complemento que extrae los nombres de personas, organizaciones y nombres de lugares automáticamente de los documentos.
“Datashare está en el centro de todo lo que hacemos en ICIJ”, dijo Romera. “Es la herramienta más importante que tenemos”.

“El intercambio de datos está en el centro de todo lo que hacemos en ICIJ. Es la herramienta más importante que tenemos ”
Pierre Romera, ICIJ
Sala de redacción digital
La segunda herramienta clave utilizada por los colaboradores del ICIJ es I-Hub, una sala de redacción digital, que aparece en todas las investigaciones. Romera describió I-Hub como una sala de redacción digital que permite a los periodistas de varios países trabajar de forma coordinada.
Los colaboradores trabajaron en grupos regionales durante la operación Pandora Papers para compartir los descubrimientos que hicieron. Otros formaron grupos para analizar los datos o desarrollar historias.
I-Hub surgió del trabajo del ICIJ en el proyecto Offshore Leaks. Un miembro del ICIJ sugirió la necesidad de una herramienta que permitiera a los periodistas trabajar juntos de manera segura y otros miembros del ICIJ estuvieron de acuerdo.
La Fundación Knight otorgó una subvención para desarrollar I-Hub a partir de una plataforma de código abierto, Oxwall, originalmente diseñada para respaldar las redes sociales y las aplicaciones de citas. Se utilizó por primera vez en la investigación de Swiss Leaks en 2015.
Para 2019, I-Hub necesitaba una actualización para permitir su uso para administrar el creciente volumen de datos que comparten los periodistas. Se trasladó a una nueva plataforma, Discourse, que ofrecía un mayor potencial de personalización.
‘No hay lugar para los egos’
Proyectos como Pandora Papers tienen éxito porque los periodistas acuerdan poner en común su información. “No hay lugar para los egos”, dijo Díaz-Struck. “Todo se basa en compartir y confiar”.
“Es importante involucrar a los periodistas en una etapa temprana”, dijo Romera. “Es necesario comprender muy rápidamente si es de interés público y si hay historias potenciales dentro de los documentos”.
Al comienzo del proyecto Pandora Papers, los miembros del ICIJ utilizaron archivos por lotes para hacer coincidir los nombres contenidos en los documentos con las “listas de países”. Estos archivos contenían los nombres de políticos, celebridades, miembros de la realeza y otras personas de interés en cada geografía.
Los periodistas también compararon los registros filtrados con datos de filtraciones anteriores, listas de sanciones y otras fuentes de datos.
El ejercicio brindó a los colaboradores una descripción general de los países y las personas que ocupaban un lugar destacado en el conjunto de datos.
“Pudieron hacer el trabajo y profundizar mucho más en los documentos, pero todo comienza dándoles algunas pistas”, dijo Romera.
Un equipo reunió datos sobre fideicomisos estadounidenses; otro trabajó para identificar y contar a todos los multimillonarios que figuran en los datos. Otros trabajaron para identificar la presencia de oligarcas rusos. Diferentes equipos de investigación se enfocaron en diferentes proveedores de servicios offshore para tratar de dar sentido a sus datos.
“De hecho, dividimos nuestro equipo de investigación de datos entre proveedores, por lo que diferentes personas se apropiaron de proveedores específicos para ver cómo podríamos estructurar esa información”, dijo Díaz-Struck.
Algunos periodistas utilizaron los documentos para investigar temas en los que ya estaban interesados. Una investigación mostró que una orden católica deshonrada, la Legión de Cristo, con 300 millones de dólares depositados en empresas offshore, había invertido millones en una empresa inmobiliaria que desalojó a inquilinos en apuros durante la pandemia. .
Aprendizaje automático
El equipo de datos y tecnología del ICIJ inicialmente pasó tiempo revisando manualmente archivos PDF enormes que se encuentran en los datos para identificar tablas de información relevante.
Los equipos pudieron automatizar el proceso mediante el uso de herramientas de aprendizaje automático basadas en Python, Fonduer y Scikit-learn, para identificar y extraer la información. Como todos los datos, era necesario revisarlos y limpiarlos manualmente.
Cuando los periodistas comenzaron a buscar los documentos, quedó claro que estaban recogiendo una gran cantidad de documentos que no eran directamente útiles.
Los datos contenían una gran cantidad de informes de diligencia debida, incluidas listas de empresas sancionadas enumeradas por la Oficina de Control de Activos Extranjeros de EE. UU. (OFAC), formularios de “conozca a su cliente” y búsquedas en World-Check, una base de datos de diligencia debida comercial.
“Fueron interesantes porque nos dicen que potencialmente [offshore service providers] estamos investigando clientes, pero los registros en realidad no significaban que esas personas estuvieran en nuestros datos ”, dijo Díaz-Struck.
El equipo de datos volvió a utilizar la tecnología de aprendizaje automático para identificar y agrupar los archivos no deseados, lo que permitió a los periodistas eliminarlos de sus búsquedas.
Pero no todos los desarrollos funcionaron según lo planeado.
Durante la investigación de Pandora Papers, Romera y su equipo desarrollaron un complemento para vincular I-Hub y Datashare que permitía a los periodistas comentar e iniciar discusiones sobre los documentos de interés directamente en la plataforma Datashare.
“Pasamos meses tratando de construir esta función”, dijo Romera. “No fue un gran éxito”.
Aún no está claro si eso se debió a que los periodistas no conocían la función o no habían sido capacitados para usarla.
“Quizás el siguiente paso sea asegurarse de que sepan que pueden comentar”, agregó.
Comprobando hechos
La verificación de hechos fue una parte importante del proyecto Pandora Papers. Cada número citado en historias públicas pasa por un escrupuloso proceso de verificación de hechos.
Se requiere una gran cantidad de trabajo para verificar, por ejemplo, que los datos filtrados contienen información sobre más de 330 políticos y funcionarios públicos en 90 países y territorios, y más de 29.000 beneficiarios reales.
Encontrar una cifra precisa del número de políticos en el conjunto de datos requirió un esfuerzo minucioso. Significaba cotejar los nombres de figuras políticas con otros datos, como sus fechas de nacimiento y los datos contenidos en los registros públicos, para asegurarse de que fueran identificados correctamente.
Los diferentes países registran las fechas, incluidas las fechas de nacimiento, por ejemplo, en diferentes formatos.
“Necesita que alguien evalúe una muestra aleatoria de datos y revise …